What is Data Science ?

Data is meaningless until its conversion into valuable information.
Data Science involves mining large datasets containing structured and unstructured data and identifying hidden patterns to extract actionable insights.
According to Wikipedia, Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from noisy, structured and unstructured data and apply knowledge from data across a broad range of application domains. Data science is related to data mining, machine learning and big data.
Who is a Data Scientist?
A data scientist is someone who creates programming code and combines it with statistical knowledge to create insights from data.
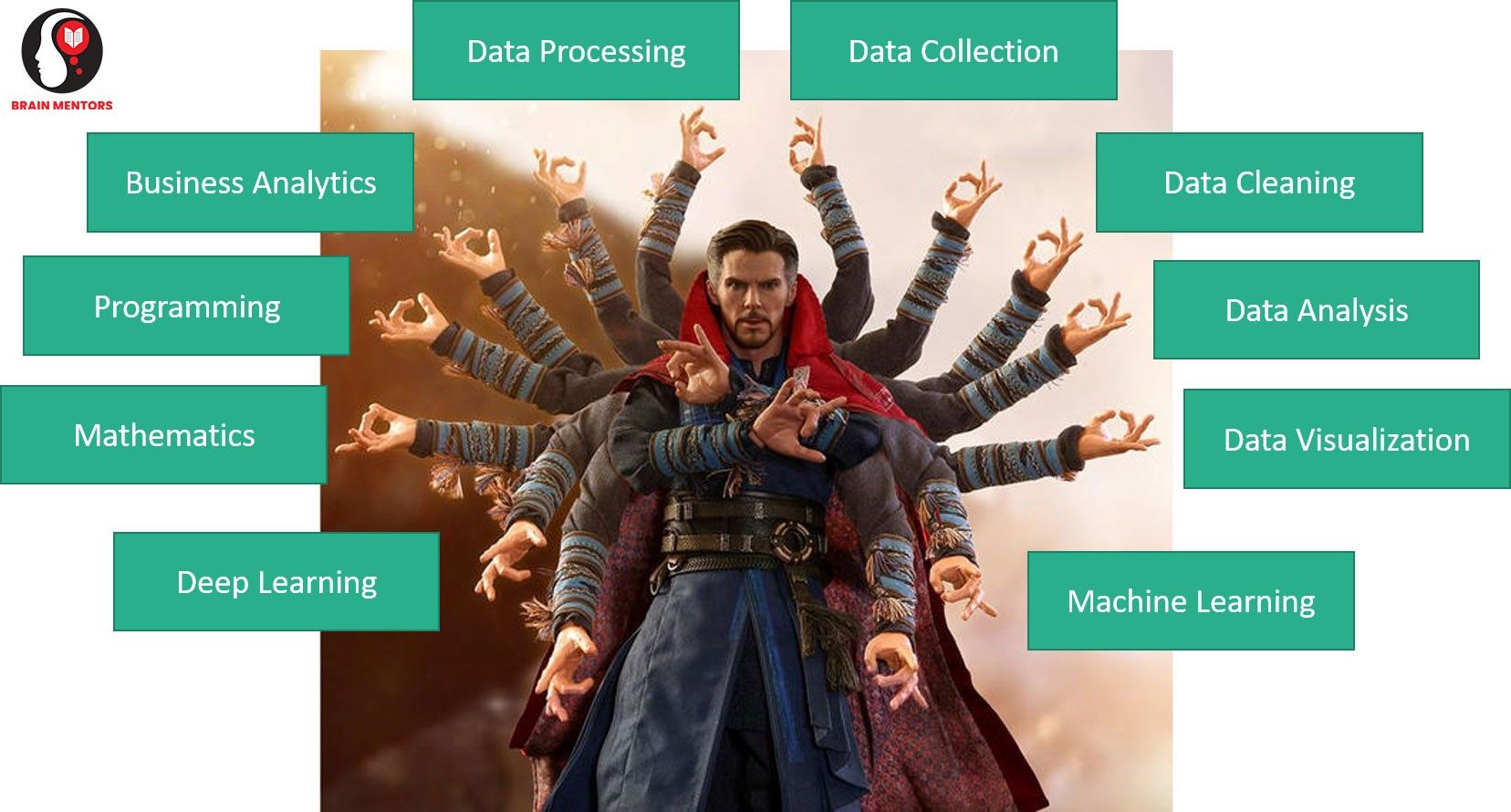
Data Science is a combination of Math and Programming Skills
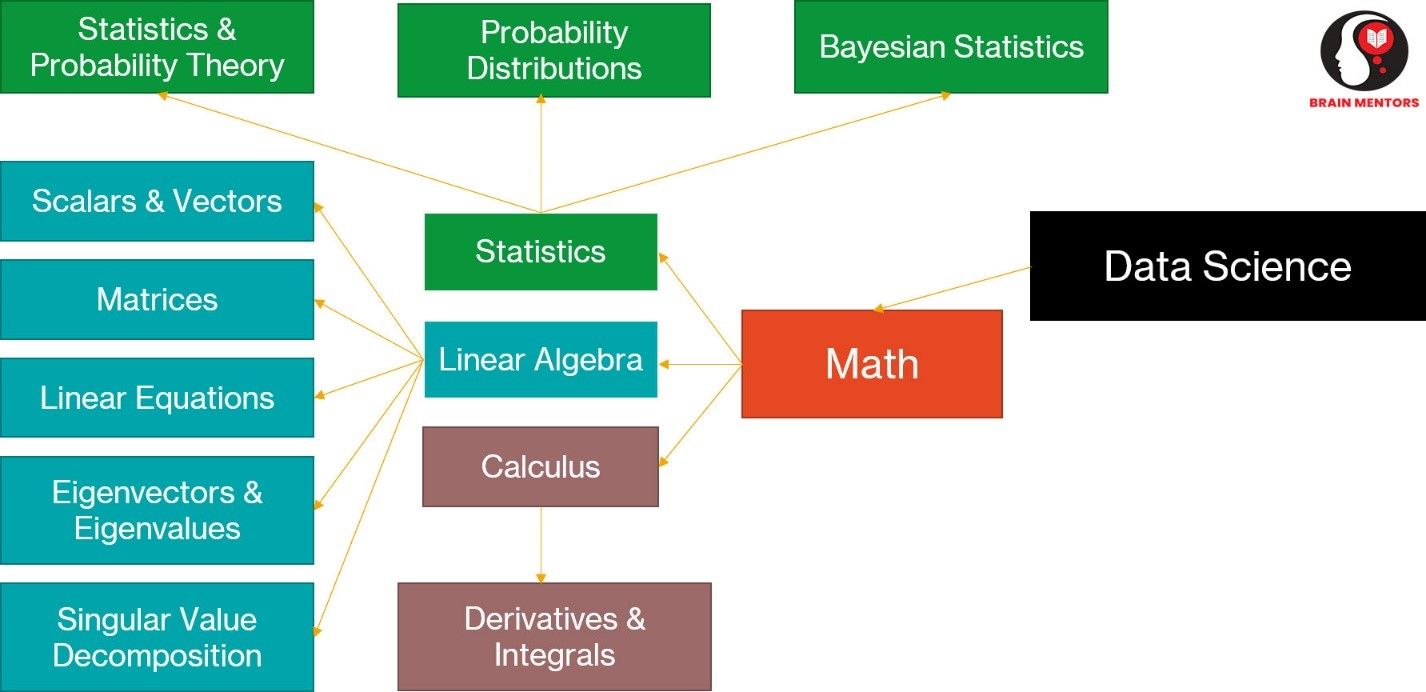
Let’s look at the Mathematics topics required for Data Science
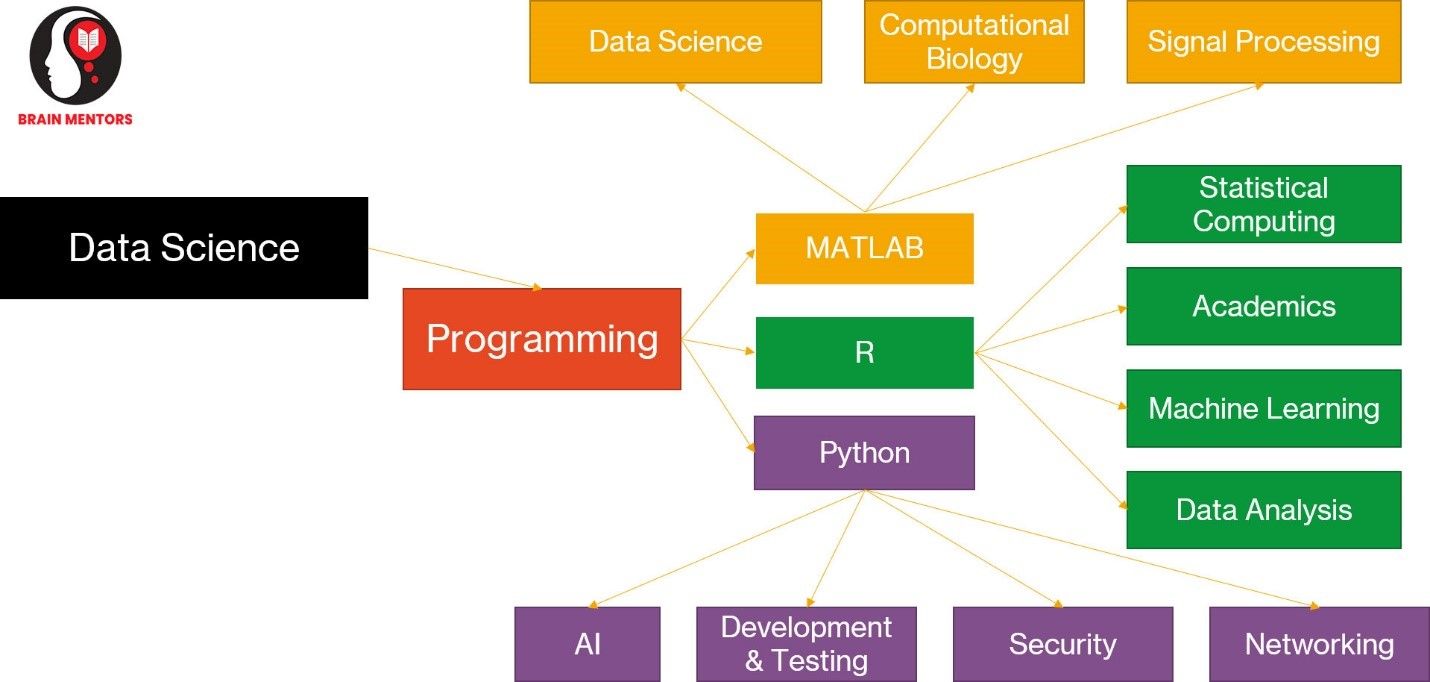
Programming required for Data Science. You can pick any one of the programming depends on your requirement.
Points to consider before choosing Programming for implementation of Data Science
- If you just want to focus on implementation part without thinking of algorithm that goes behind then you can go with R programming or MATLAB
- If you want to write your own algorithms then you can go for Python Programming
- If you are not from programming background and do not bother about details of programming concepts then go for R programming
- For Signal Processing, Computation biology MATLAB is a better option
- For Statistics, Data Analysis and Visualization or academics choose R Programming
- For Machine learning and Deep Learning detailed implementation go for Python Programming
- Python is best for writing algorithms of Machine Learning & Deep Learning
Data Science life cycle:
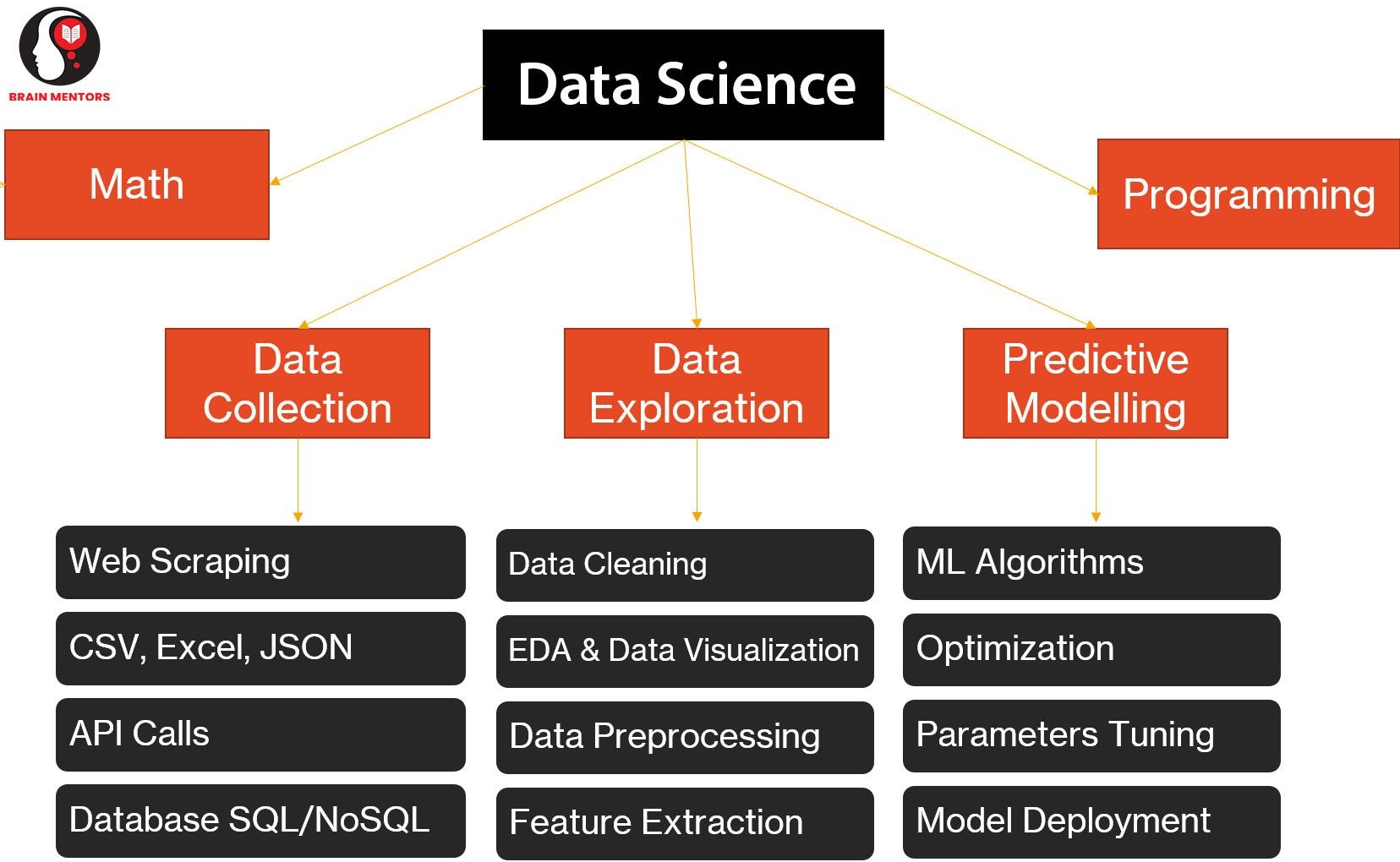
-
Data Collection
- Database- MySQL / Oracle / NoSQL
- Files - Excel / CSV / Raw Text / Images / Audio / Video
- API Calls
-
Data Analysis
- Data Cleaning
- Statistical Analysis
- EDA - Exploratory Data Analysis
- Data Visualization
-
Data Preprocessing
- Feature Scaling - Normalization & Standardization
- Label Encoding & OneHot Encoding
- Train Test Split
-
Machine Learning - Predictive Modeling
-
Supervised
-
Regression
- Linear Regression
- Polynomial Regression
- Support Vector Regression
- Decision Tree Resgression
- Regularization - Ridge / Lasso
- PLS - Partial Least Square
- Still lot more techniques are there....
-
Classification
- Logistic Regression
- KNN - K Nearest Neighbors
- Naive Bayes
- Support Vector Classification
-
Decision Tree Classification
-
Bagging
- Simple Bagging
- Random Forest
-
Boosting
- AdaBoost
- Gradient Boosting
- XGBoost
-
Bagging
-
Regression
-
Unsupervised
-
Clustering
- K-Means Clustering
- Hierarchical Clustering
- DBSCAN
- MEAN Shift
- K-Medoids
- BIRCH
- Spectral Clustering
- Agglomerative Clustering
-
Clustering
-
Dimensionality Reduction
- PCA - Principle Component Analysis
- LDA - Linear Discriminent Analysis
- t-sne - t-distributed stochastic neighbor embedding
-
Supervised